언제까지 기본 모델만 쓸거야? - 오픈 데이터로 YOLOv11 시작하기 🚀
- AI
- YOLO
- 딥러닝
오늘 할거
오늘은 인터넷에서 공개된 데이터를 가져와 나만의 모델을 만드는 방법을 소개하려고 해요.
최근 공개된 YOLOv11을 통해 최신 기술을 경험해보고 튜토리얼을 진행해보면 좋을 것 같아서 준비하게 되었어요.
YOLO(~~욜로할 때 그 욜로 아님.~~)는 실시간 객체 탐지(Realtime Object Detection) 분야의 대표적인 딥러닝 모델이에요.
2016년 첫 발표 이후, 올해 v11까지 정말 다양한 모델들이 등장했는데요. 당시에는 주로 R-CNN 계열을 비롯한 Two-stage 방식의 모델들이 주류를 이루었지만, YOLO는 One-stage 방식을 채택해 기존 모델들이 지녔던 속도 한계를 극복한 혁신적인 기술이었습니다.
이런 의미에서 "You Only Look Once (한 번만 보면 된다!)"라는 이름이 붙게 되었죠.
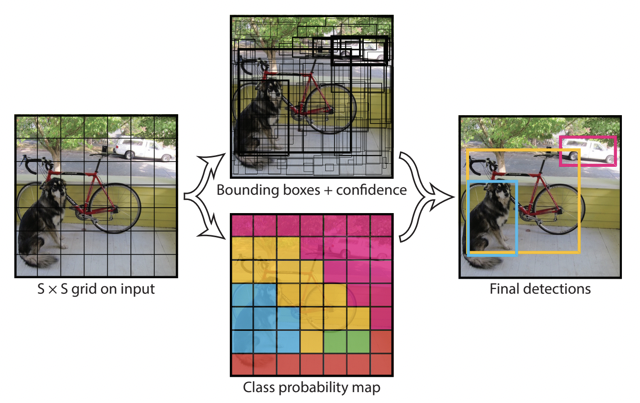
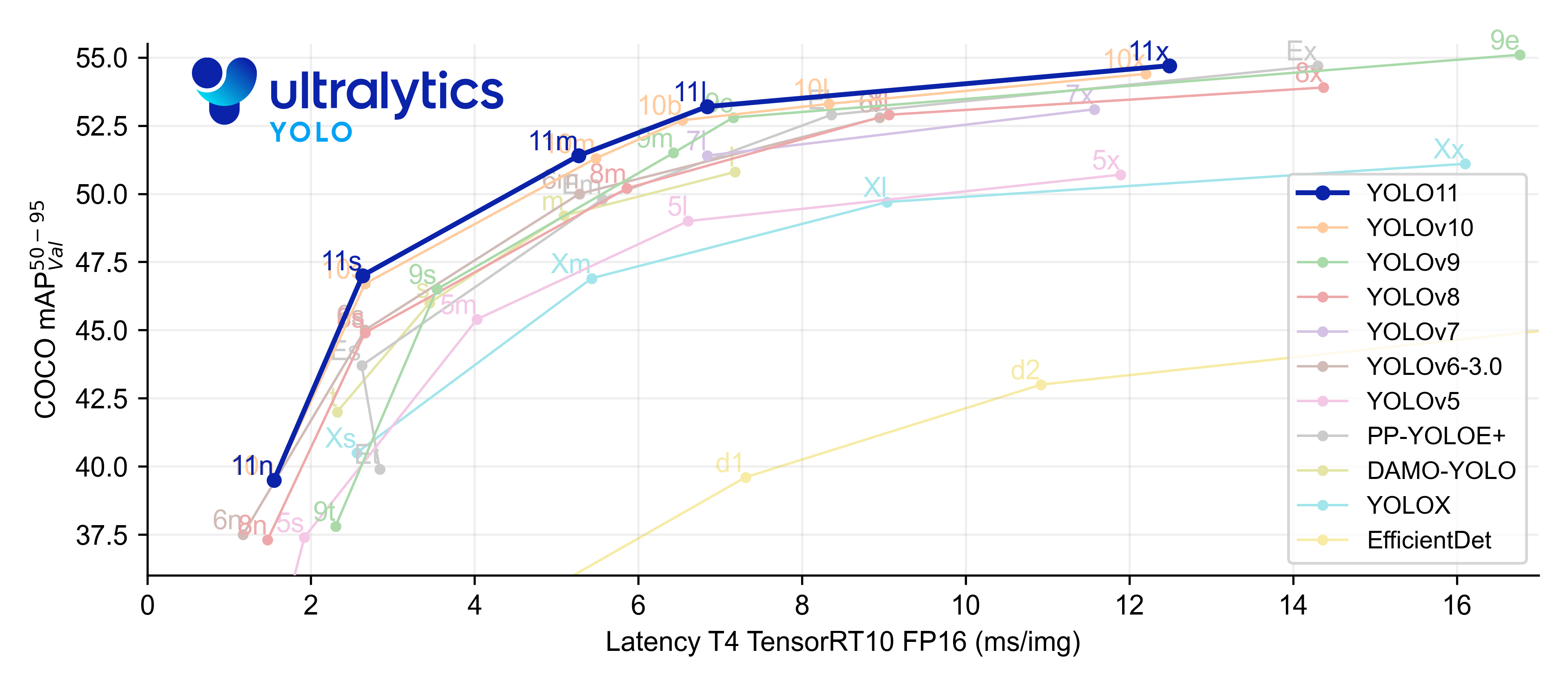
현재 최신 버전인 YOLOv11은 이전 버전들에 비해 높은 정확도와 빠른 추론 속도를 기록하며, 모든 YOLO 버전 중 가장 우수한 벤치마크 성적을 보여줬어요.
이 모델은 Ultralytics에서 제공하는 라이브러리를 통해 추론, 학습등의 작업을 수행할 수 있어요. 모델의 학습 추론, 최적화 등에 대한 자료도 함께 포함되어 있으니, 직접 가셔서 학습하는 시간을 가지시는 것도 추천드려요! Ultralytics official
 오늘은 이 라이브러리와 YOLOv11모델을 베이스로 나만의 모델을 만들어보는 시간을 가져볼게요!
오늘은 이 라이브러리와 YOLOv11모델을 베이스로 나만의 모델을 만들어보는 시간을 가져볼게요!
개발환경 구성
사용 언어와 라이브러리는 아래와 같아요.
- 구성
- OS : Ubuntu 24.04 LTS
- GPU : RTX-4070Ti-Super
- nvidia 드라이버 : 555.42.06
- 드라이버 버전은 여러분들 GPU에 맞는 드라이버 쓰시면 되고, 다만 나중에 사용할 라이브러리에 대한 종속성이 있으니, 반드시 설치는 해주셔야해요!
- 사용 언어 및 라이브러리
- python 3.12.8
- ultralytics
라이브러리 종속성을 많이 타는 분야이다 보니 , 가상환경 구성 후 설치 하는 것을 추천드려요. pyenv 및 venv 설정은 설명해주신 분들이 많으니 구글에서 찾아봐요!
$ pyenv --version
$ pyenv --local 3.12.8
$ python -m venv .venv
$ source .venv/bin/activate
$ python -m pip install --upgrade pip
$ pip install ultralytics
설치가 다 되었다면, 아래의 python 코드를 통해 체크해봐요.
import torch
from ultralytics import YOLO
print(torch.cuda.is_available()) #gpu 사용하시는 분들은 false가 확인될 시 cuda 드라이버 설치를 확인해 주세요!
# 기본 n 모델을 로드. (자동으로 다운로드 됩니다!)
model = YOLO("yolo11n.pt")
# 가지고 있는 아무 이미지파일의 경로를 통해 테스트 해봐요!
results = model("./desk.jpg",save=True)
저는 제 사무실 책상사진을 한장찍어서 테스트 해 봤어요.
 결과가 어찌 됐든, 개발환경이 잘 동작한다는 것을 확인했어요.
결과가 어찌 됐든, 개발환경이 잘 동작한다는 것을 확인했어요.
데이터 찾기
데이터는 튜토리얼이니, 라벨 컨트롤이나 추가 작업이 필요없도록, YOLO 형식의 데이터 셋을 kaggle에서 찾아왔어요. 데이터 셋 링크
혹시 라벨은 되어있지만, YOLO 형태의 데이터가 아니라 학습이 어려우신 분들은 아래 링크를 참고해 보세요! YOLO 형태의 데이터 셋으로 처리하는 방법 링크
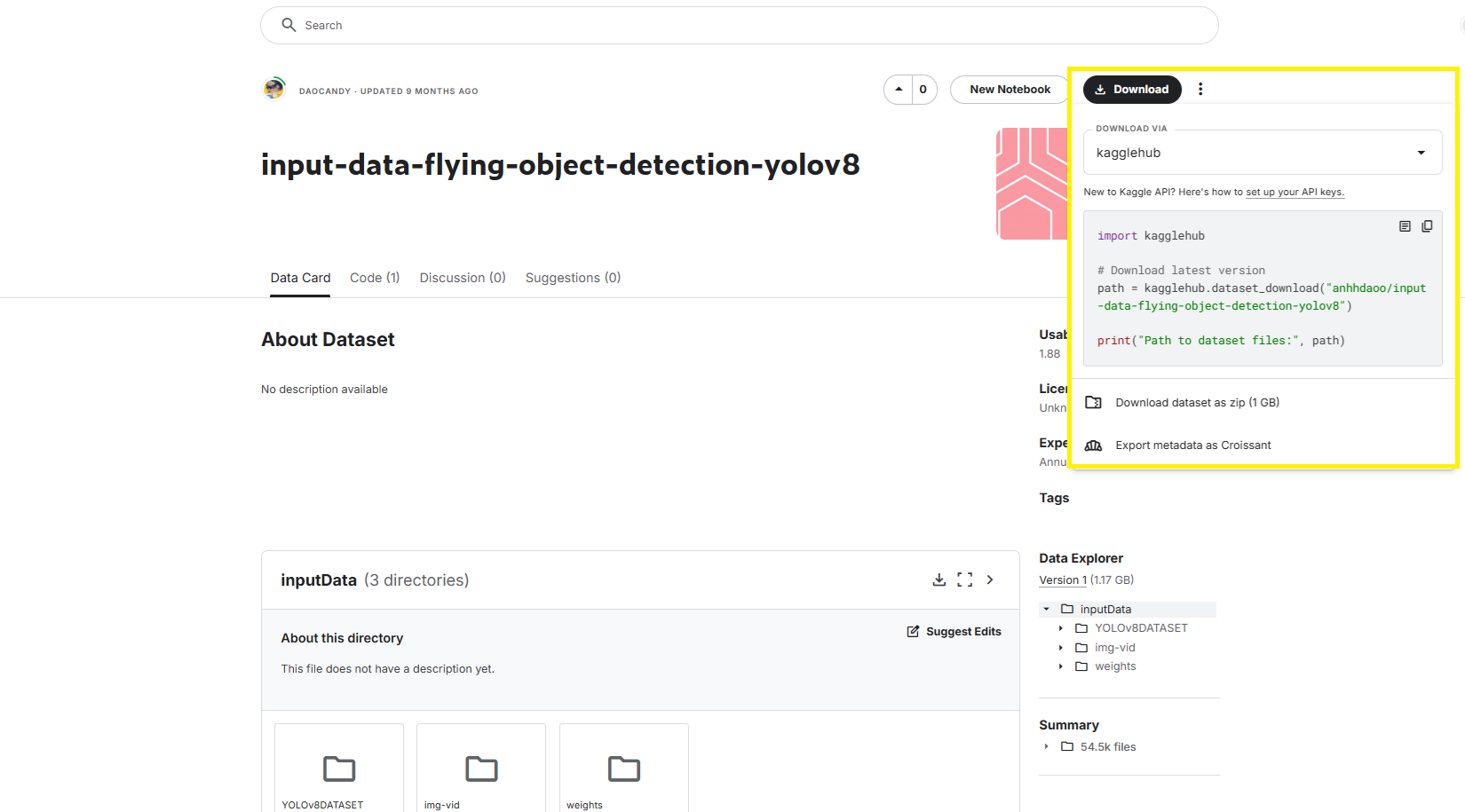
우측상단에서 kaggle python 라이브러리를 설치하여 사용하시거나, zip 파일로 직접 받아볼 수 있어요.
저는 라이브러리까지는 필요하지 않아서 zip 파일로 직접 다운로드 했어요. 압축을 풀어주면 아래와 같은 구조를 가지고 있는데, 우리는 YOLOv8DATASET의 drone-detection-new.v5-new-train.yolov8 데이터셋만 사용할 거에요.
YOLO 데이터 셋 설명
YOLOv8 ~ YOLOv11 학습을 위한 데이터 셋의 일반적인 형태는 아래와 같아요.
- YOLODataset
- images
- train
- test
- val
- labels
- train
- test
- val
- dataset.yaml
- images
우리가 받아온 데이터 셋도 디렉토리 이름만 다를 뿐, 동일한 형태를 가지고 있음을 알 수 있어요.
 자, 이제 우리가 학습을 위해 몇가지 수정할 사항이 있어요. 이 단계만 끝나면 드디어 학습을 할 수 있게 되는 것이죠.
자, 이제 우리가 학습을 위해 몇가지 수정할 사항이 있어요. 이 단계만 끝나면 드디어 학습을 할 수 있게 되는 것이죠.
-
data.yaml
train: ../train/images val: ../valid/images test: ../test/images nc: 3 names: ['AirPlane', 'Drone', 'Helicopter'] roboflow: workspace: ahmedmohsen project: drone-detection-new-peksv version: 5 license: MIT url: https://universe.roboflow.com/ahmedmohsen/drone-detection-new-peksv/dataset/5
-
경로수정
- dataset에 대한 base path를 설정해요.
- 기존에는 상대경로이나, 이왕이면 절대 경로로 변경하는 것을 권장드려요.
- 패키지로 잘 잡혀있는 상황이라면 상대경로도 무방해요.
- 클래스 정보 확인
- nc를 확인해 보면, 이 데이터 셋에는 총 3 개의 클래스가 있음을 알 수 있어요.
- 아래의 names에서는 각 클래스 명을 알 수 있고, 이 클래스는 순서대로 0,1,2.. 순서의 클래스 번호를 가져요. 나중에 추론 결과를 후처리 할 때 이 정보를 사용하여 클래스 명을 바꿔서 출력하는 등의 작업하는 데 사용할 수도 있어요.
- 불필요 정보 삭제
- roboflow에 대한 정보는 roboflow플랫폼에서 사용하기 위한 정보들이니, 현재 우리가 로컬에서 사용하기에는 불필요한 정보이니 삭제해주도록 해요.
- 최종적으로 수정 된 data.yaml은 다음과 같아요.
- window의 경우 "/"가 잘 적용이 안될 수 있으니, "\\"를 사용하여 경로를 작성해 주세요!
train: itivai-1/Projects/demoprojects/dronData/drone-detection-new.v5-new-train.yolov8/train/images val: itivai-1/Projects/demoprojects/dronData/drone-detection-new.v5-new-train.yolov8/valid/images test: itivai-1/Projects/demoprojects/dronData/drone-detection-new.v5-new-train.yolov8/test/images nc: 3 names: ['AirPlane', 'Drone', 'Helicopter'] - dataset에 대한 base path를 설정해요.
학습
자, 드디어 모든 준비가 끝나고 학습할 준비가 되었어요! 아래의 코드를 복붙하면 바로 학습할 수 있지만, 하나하나 우선 설명 드릴게요!
import torch
from ultralytics import YOLO
str_device = 'cpu'
# gpu 사용 가능 여부 체크를 통해 사용할 device 설정
if(torch.cuda.is_available()):
str_device = 'cuda'
else:
str_device = 'cpu'
# 사용할 모델(알고리즘)설정. 자동 다운로드
model = YOLO("yolo11n.pt")
train_args = {
"data": "/home/itivai-2/project/demoproject/dron/drone-detection-new.v5-new-train.yolov8/data.yaml",
"epochs": 100,
"batch": 16,
"project": "train_results",
"pretrained": False,
"device": str_device
}
# 모델 학습 시작
model.train(**train_args)
-
model = YOLO("yolo11n.pt")
- 사용할 모델 객체를 생성해요.
- 파라미터로는 ultralytics에서 제공하는 형태로 모델 명을 적으면 그 모델을 알아서 현재 워크스페이스에 다운로드 해줘요.
-
train_args
- 학습 시 필요한 정보들(dataset 경로, epoch 횟수 등등..)을 가지고 있어요. train()내부에 파라피터로 입력하셔도 무방해요. 저는 가독성을 위해 **kwargs를 사용하여 입력해 줬어요.
- data : 지정한 데이터 셋의 경로
- epochs : 진행할 epoch 횟수
- batch : batch size (1 iteration에 사용할 데이터 개수)를 설정하기 위한 파라미터에요. 혹 gpu 메모리 크기가 부족하시다면,1,4,8 이렇게 조금씩줄여보면서 적합한 크기를 찾아야 할 수 있어요!
- batch_size가 궁금하다면?(링크)
- project : 학습 결과를 저장할 디렉토리 경로
- pretrained : 현재 로드한 모델을 사전 학습된 모델로 사용할지 여부를 결정하는 파라미터에요. 이번에는
- device : 작업을 수행할 디바이스를 지정하는 파라미터에요.('cpu' / 'cuda' / gpu 번호)
- 이 외에도 train함수의 파라미터로 넣을 수 있는 종류가 많지만, 이번에는 튜토리얼을 목적으로 하는 글이니, 가장 마일드하게 세팅해 봤어요.
- 학습 시 필요한 정보들(dataset 경로, epoch 횟수 등등..)을 가지고 있어요. train()내부에 파라피터로 입력하셔도 무방해요. 저는 가독성을 위해 **kwargs를 사용하여 입력해 줬어요.
-
model.train(**train_args)
- 학습을 실행하는 코드에요. 선언해둔 train_args를 파라미터로 넣어줬어요.
자 모든 설명이 끝났어요! 이제 코드를 실행시켜 볼까요?
코드를 실행하면 우선 모델을 다운로드 하게되고, 데이터 셋을 읽어들여요. 그 후 지정 된 batch size를 통해 epoch 별 iteration을 설정하고, 학습에 들어가게 되죠. 이제 우리가 할 일은 한숨 자고와서 결과를 확인하기만 하면 되요!
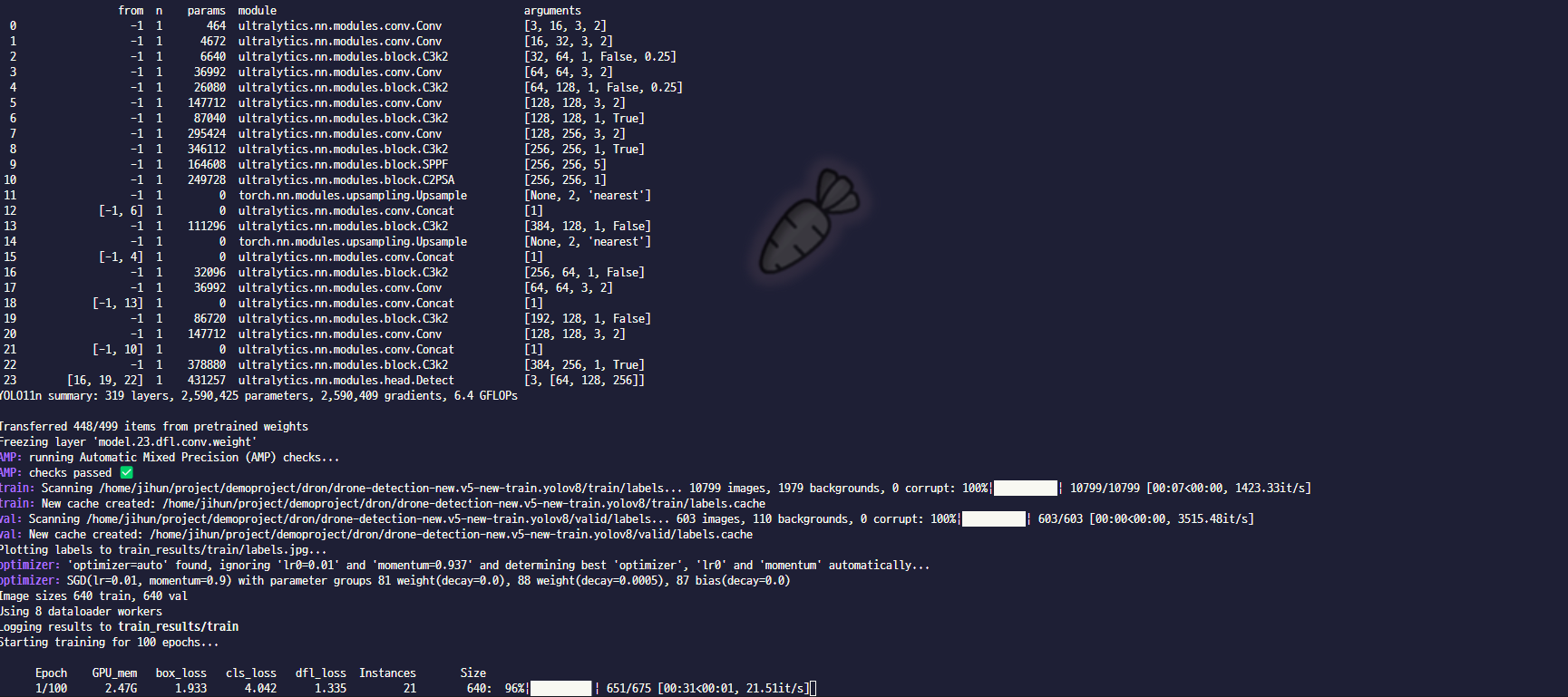
학습 결과 설명
-
train_results
- 학습이 완료되면, 아까 우리가 지정한 학습 결과 폴더에 여러 지표들과 학습된 모델이 생성되었을 거에요!
- best.pt와 last.pt
- 모델은 이렇게 두가지가 생성되었는데, best.pt는 전체 epoch 중 최고 성능을 보였던 가중치 , last.pt는 가장 마지막 가중치가 저장된 모델이에요.
-
labels.jpg
- 데이터 셋에서 각 클래스 별 수량 및 분포를 나타내요.
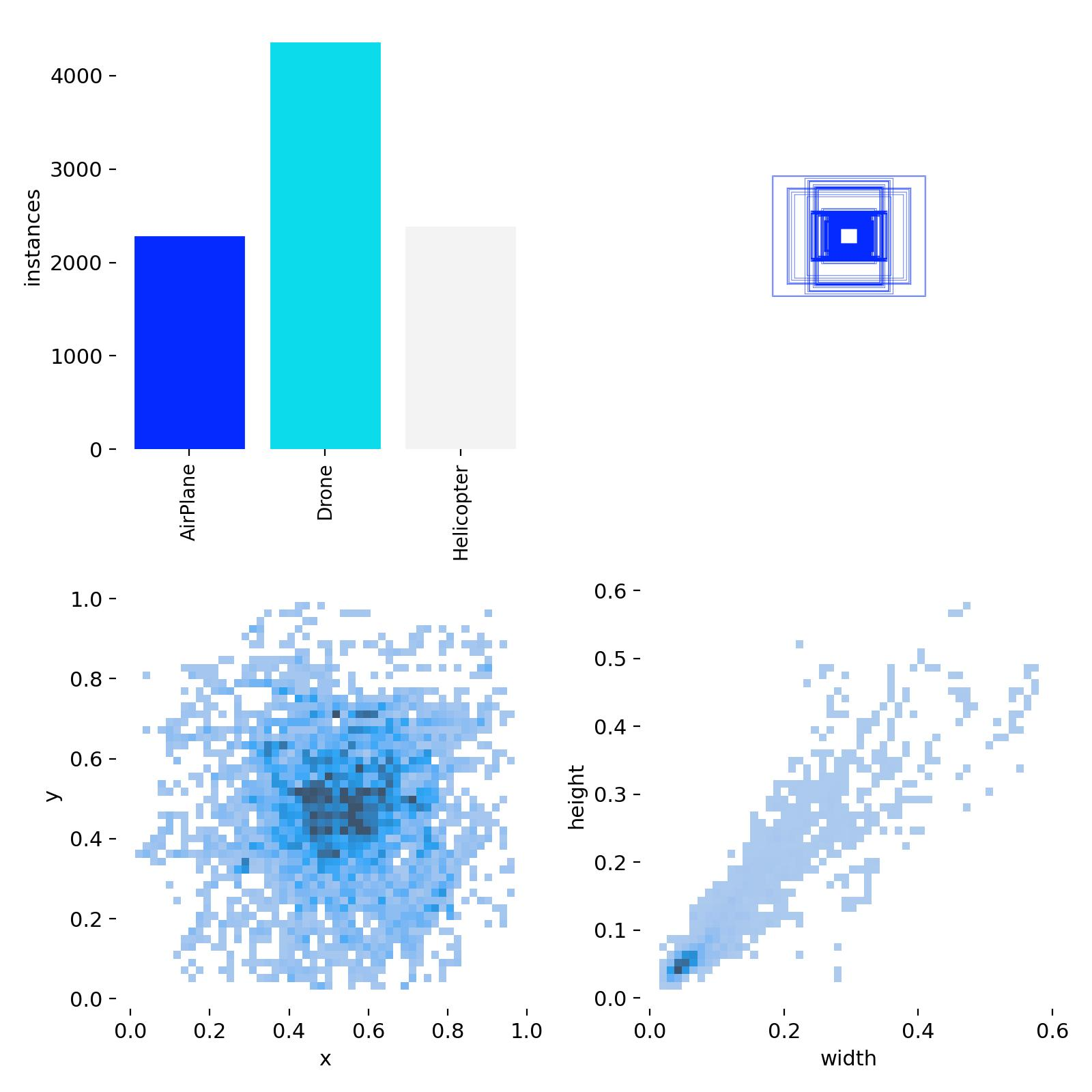
- 데이터 셋에서 각 클래스 별 수량 및 분포를 나타내요.
-
Precision-Recall Curve
- 모델의 성능 지표 중 하나로, Precision 대 Recall 수치를 보여줘요. 이를 통해 모델의 대략적인 성능인 mAP 지수를 계산할 수 있어요.
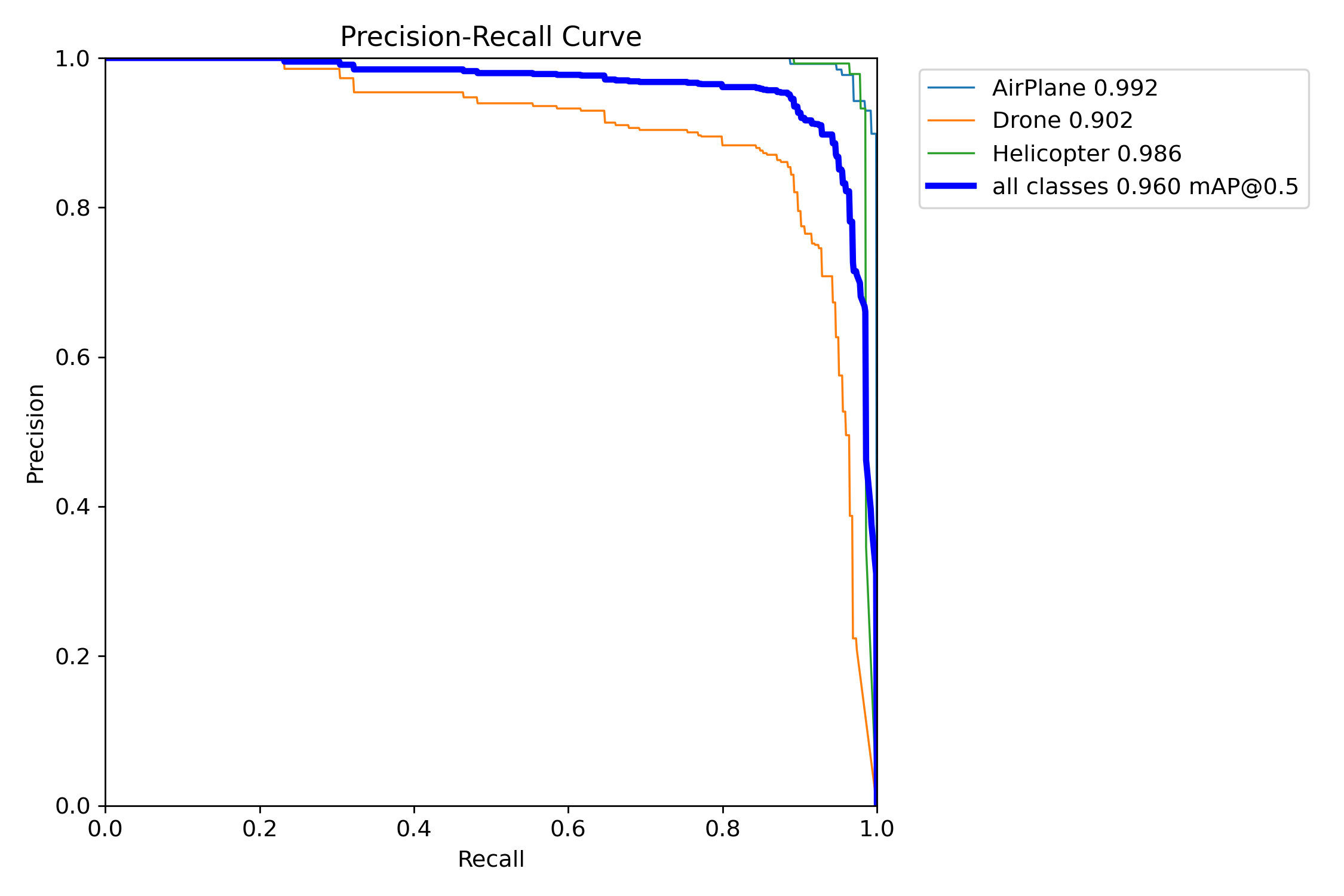
- 모델의 성능 지표 중 하나로, Precision 대 Recall 수치를 보여줘요. 이를 통해 모델의 대략적인 성능인 mAP 지수를 계산할 수 있어요.
-
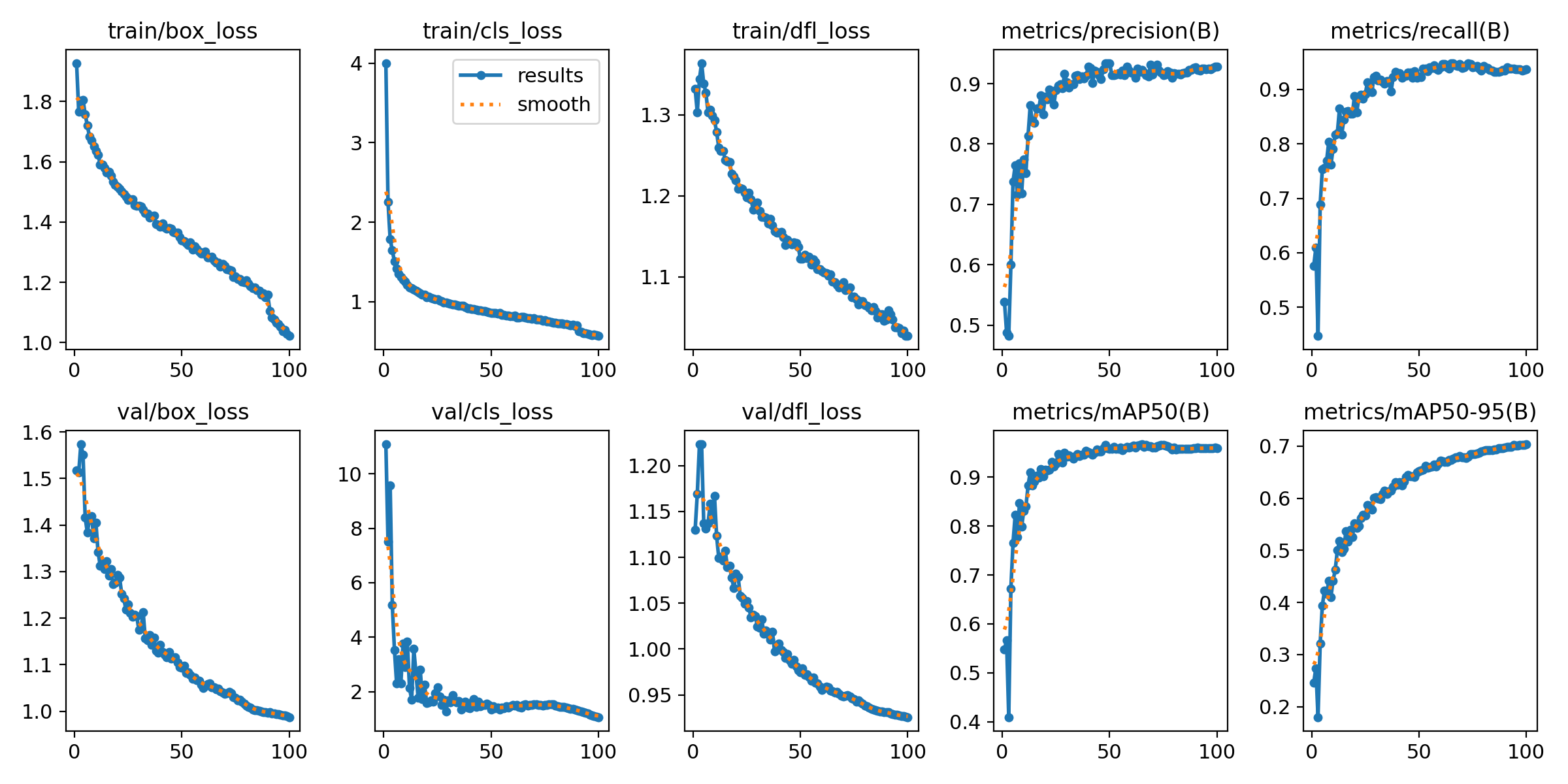
results.png
-
학습 진행 간 Epoch 별 성능 변화 추이를 종합적으로 확인할 수 있어요.
-
그래프 들을 확인해 보았을 때, 학습이 진행 됨에 따라기울기가 점차적으로 줄어든다면 의도한 대로 학습이 잘 진행되었다고 볼 수 있어요. 이 기울기를 통해서 epoch을 추가로 더 진행해야 할지, 또는 다른 변수를 건드려야할지 결정할 수 있어요.
-
현재 결과를 보았을 때는 기울기가 잘 줄어들 고 있지만, 아직까지 기울기가 충분히 줄어들지 않은 지표들(train/box_loss, metrics/mAP50-90(B) 등)이 확인되는 바, 학습을 조금 더 진행해볼 여지가 있겠다! 라는 생각을 할 수 있죠.
-
추론 방법
드디어 마지막이에요! 이제 우리가 만든 모델을 실제로 구동해 보면서 성능을 확인해 볼까요? 추론 방법은 우리가 만든 모델로 YOLO 객체를 생성한 후, 원하는 데이터에 대해 추론할 수 있어요!
import torch
from ultralytics import YOLO
str_device = 'cpu'
# gpu 사용 가능 여부 체크를 통해 사용할 device 설정
if(torch.cuda.is_available()):
str_device = 'cuda'
else:
str_device = 'cpu'
# 사용할 모델(알고리즘)설정. 자동 다운로드
model = YOLO("./train_results/train/weights/best.pt")
model.predict(source = "./vid-droneEdit.mp4",save=True)
결론
자 그러면 코드를 실행시켜서 추론한 결과를 확인해 볼까요?

음.. 생각보다 결과가 좋지 않죠? 모델에 성능에 대해 우리가 학습에 사용한 데이터는 약 280MB. 10000장 남짓의 이미지에요. 또한 사용한 모델도 학습 속도를 위해 가장 가벼운 모델인 yolov11n 모델을 사용했어요. 또한 epoch도 100회 정도만을 주었죠. 그 결과 학습 결과 그래프에서도 아직 완성되지 못한 포인트 들이 보였고, 아직까지는 일반화 성능이 잘 나타나지 않고 있어요.
이런 문제는 데이터 추가, 알고리즘(모델 크기)변경, 학습 인자 수정 등의 작업 등을 통해 개선할 수 있어요.
하지만 오늘의 주제는 나만의 모델을 만드는 법이기 때문에, 우리가 데이터를 가지고 모델을 학습 시켰다! 라는 것에 의의를 두고, 이만 마치도록 할게요.